Why I made claudeleaks.com, what it tracks, and why it matters more than most people realize.
On March 31, 2026, a researcher named Chaofan Shou at FuzzLand was looking at Claude Code's npm package and found something that shouldn't have been there.
A 57MB .map file. Pointing to a public Cloudflare R2 bucket. Containing roughly 512,000 lines of TypeScript spread across 1,906 files. Anthropic's proprietary codebase for Claude Code, sitting there, fully accessible to anyone who knew where to look.
The disclosure tweet got over 3 million views. Mirrors appeared on GitHub within hours. Developers were in the repos pulling apart the architecture, reading the feature flags, annotating the internal module structure. Hacker News lit up. Security journalists picked it up.
And if history is any guide, in a few weeks, most people will have forgotten the specifics entirely.
That's the pattern. And that's exactly why I built claudeleaks.com.
This Isn't the First Time
What makes the March 2026 leak remarkable isn't just the scale, though 512,000 lines of production TypeScript is a lot. What makes it remarkable is that it's the second time Anthropic shipped Claude Code's source code by accident.
In February 2025, on the very first day of the Claude Code beta, a developer named Dave Schumaker noticed inline source maps embedded inside the published npm package. He recovered the code from Sublime Text's undo history after Anthropic pulled the package. DMCA notices followed. GitHub forks got taken down. TechCrunch covered it.
Wave 1. Then Wave 2, over a year later, and this time significantly larger.
These two incidents aren't separate stories. They're the same story playing out twice. And without a place that tracks both of them together, with sources, context, and the full timeline, you end up with two disconnected viral moments instead of a pattern that tells you something meaningful about how this tool has been packaged, what the failure modes look like, and what's worth paying attention to going forward.
That's the gap I built claudeleaks.com to fill.
AI Security Has a Memory Problem
There's a specific way AI security stories tend to play out online. Something surfaces. A researcher posts about it. The replies go wild. It trends for half a day. Someone writes a hot take thread. Another person dunks on the company. A few journalists pick it up, usually without the full technical context. And then the next news cycle starts and the whole thing evaporates.
This pattern isn't unique to AI, but it's worse here for a few reasons.
AI security incidents are genuinely complex. A vulnerability in Claude Code isn't the same category of thing as a data breach or a phishing campaign. The attack surface involves prompt injection, tool use, file system access, shell execution, IDE integrations, npm packages, API keys, model behavior under adversarial input. Explaining that accurately takes more than a tweet. And most of the people who could explain it properly are the researchers who found the issue, not the journalists writing about it.
So what usually gets preserved isn't the finding. It's the drama around the finding.
The Wave 1 source code story became about Anthropic's DMCA response, not about how Bun's default bundler config combined with a packaging oversight shipped inline source maps to thousands of developers. The WebSocket authentication bypass in the Claude IDE extension got a few security-focused posts and then went quiet, even though it was a confirmed CVSS 8.8 vulnerability where any malicious website could connect to your editor and start reading files.
These things matter. They should be findable. They should be documented properly.
What I Built and Why
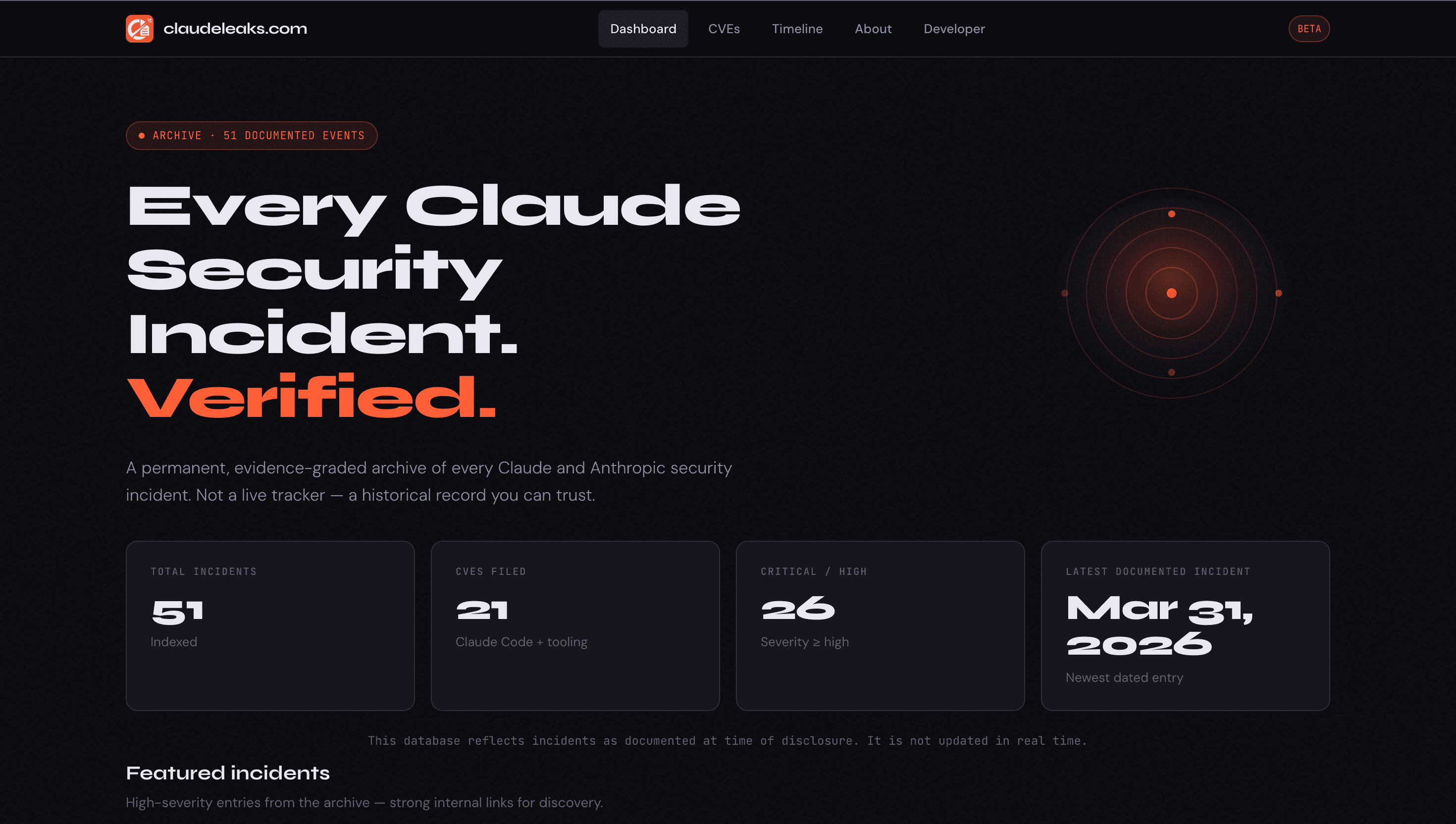
Claudeleaks.com is an archive. That's the simplest description. It's a structured, sourced, evidence-graded database of security incidents, vulnerabilities, leaks, and findings related to Claude and Anthropic's ecosystem.
It tracks CVEs with CVSS scores, affected versions, and fix information. It tracks source code leaks, system prompt extractions, prompt injection chains, misuse campaigns, and official disclosures. It tracks the legal aftermath, the DMCA notices, the GitHub takedowns. Every entry has a confidence level attached to it so you know what kind of claim you're actually looking at.
I built it because I kept running into the problem I just described. I'd try to look something up, find a reference in a Reddit comment, chase it to a dead link, dig through someone's tweet thread to find the original source, and eventually piece together half the story. The research already existed. Someone had already done the hard work of finding and verifying the thing. What was missing was somewhere for it to live that wasn't a Twitter thread or a personal blog post that might disappear next week.
I also built it because I think AI security history is worth taking seriously, and taking it seriously means keeping a proper record.
The Confidence Problem
One thing I wanted to get right was how the site handles certainty.
Not every AI security claim is created equal. Some things are confirmed. Anthropic acknowledged the issue, a CVE was filed, a patch was released, the disclosure went through proper channels. Some things are credible but unconfirmed, multiple researchers reported the same behavior independently but there was no official acknowledgment. Some things come from a single researcher, plausible and worth noting but not yet independently verified. And some things are genuinely speculative, interesting enough to mention but far from established fact.
The problem with most coverage is that these categories get flattened. A speculative finding gets reported the same way as a patched CVE. Screenshots spread without context. Community theories take on the weight of confirmed facts because the nuance gets lost in the repost chain.
So every incident on the site has a confidence grade. Confirmed. Credible. Community. Speculative. It's a simple system but it forces a kind of intellectual honesty that's usually missing. You can filter by confidence level. You can decide for yourself what you want to take seriously and what you want to treat with skepticism.
I'm not trying to be sensational about any of this. The goal is the opposite: to be boring and rigorous in a space that tends toward hype.
The CVEs Are Not What You'd Expect
When most people think about CVEs, they think about enterprise software or operating systems. Not AI coding agents. The idea that a tool you install to help you write code could have authentication bypasses, path traversal vulnerabilities, shell injection bugs, and DNS exfiltration issues feels jarring.
But that's exactly what's in the record for Claude Code.
There's a path traversal vulnerability where naive prefix matching allowed escaping restricted directories. There's a command injection where sanitization gaps let attackers chain shell commands between whitelisted operations. There's a file read plus DNS exfiltration bug. There are supply chain issues. There's an IDE WebSocket server that, for a period, accepted connections from any website without any authentication, meaning a tab you had open in your browser could reach into your editor.
Most of these are patched. That's worth saying clearly. The researchers who found them reported responsibly, Anthropic fixed them, and the patches shipped. But patched doesn't mean irrelevant. Understanding what went wrong, how it was discovered, and what the fix looked like is the entire point of maintaining a security record. Organizations learn from documented failures, their own and other people's. Developers learn to watch for the same class of issues. Researchers learn what kinds of things are still worth looking at.
The archive has 21 CVEs documented, covering Claude Code and related tooling from 2025 into 2026. The number keeps growing because the ecosystem keeps growing and the attack surface keeps expanding.
Credit Actually Matters
Here's something that gets lost in the noise. The researchers who find these things often don't get lasting credit for their work.
A blog post about a finding might get a thousand views in the first two days and then settle into obscurity. The GitHub advisory gets filed. The CVE database gets an entry with enough technical detail to be useful but not enough context to understand the full story. The Twitter thread where the researcher explained their methodology gets buried under newer content.
I wanted to fix that, at least in a small way.
Every incident on the site credits the person who found it. Chaofan Shou at FuzzLand gets credit for the March 2026 source map exposure. Zander Mackie at Datadog Security Labs gets credit for the WebSocket authentication bypass. Elad Beber at Cymulate gets credit for the directory escape and command injection findings. Dave Schumaker gets credit for recovering the Wave 1 source maps from Sublime Text's undo history, which is honestly one of the more creative pieces of security research I've come across.
These people did real work. They found real issues. A permanent record that attributes their findings correctly is a small thing, but it's the right thing.
Why This Matters More as AI Gets More Capable
There's a bigger picture here that I think about a lot.
The tools in the Claude ecosystem aren't static. Claude Code can read and write files, execute shell commands, interact with your IDE, make API calls, handle secrets, and act autonomously across long tasks. That's genuinely useful. It's also a large and growing attack surface.
As AI coding agents become standard parts of developer workflows, understanding their security history isn't optional context anymore. It's the same kind of due diligence you'd do before adopting any powerful tool with system access. What vulnerabilities have been found? How were they discovered? How quickly were they patched? What classes of attacks are researchers focused on? What source code has been exposed and what does that exposure mean for the people building on top of it?
The people who need to answer those questions don't currently have a great place to go. They have NVD, which has the CVE records but minimal context. They have GitHub advisories, which are useful but incomplete. They have old tweets and blog posts, if they can find them.
Claudeleaks is an attempt to give that audience a better starting point. Not a definitive authority, not a threat intelligence platform, just a well-organized archive that takes the existing public research and makes it actually navigable.
What the Site Actually Looks Like
The homepage shows you statistics at a glance: total incidents, CVE count, how many are critical or high severity, when the most recent documented event happened. From there you can filter by type, severity, and confidence level, search across the full archive, or jump to the CVE index specifically.
Each incident gets its own page with the full write-up: a technical summary, a more detailed description, the discoverer's name, primary sources, external links to advisories and articles and DMCA notices, severity and confidence badges, and related incidents if there are similar findings worth reading alongside it.
There's a timeline view that maps everything visually across 2023 to 2026, organized by incident type with dot sizes scaled to severity. It's a quick way to see how the landscape has evolved and how quickly things have changed in just a couple of years.
The CVE table is sortable, filterable by year and CVSS range, and exportable to CSV if you want to work with the data yourself.
None of this is complicated. That's the point. The research was already out there. The job was just to organize it.
A Note on What This Isn't
Claudeleaks is not affiliated with Anthropic. It's not a gotcha project or an attempt to make anyone look bad. It's not a live monitoring service or a threat intelligence feed.
It's a research archive I maintain because I think AI security history deserves the same kind of documentation that other parts of software security history have had for years. The security community has always understood that a proper public record of failures makes everyone more secure. That culture needs to exist in the AI space too.
If you're a developer who uses Claude Code or builds with the Claude API, this site exists for you. If you're a security researcher working on AI systems, this site exists for you. If you're just someone curious about what actually happens behind the scenes when AI companies make mistakes, this site is for you too.
Go Look at It
The site is at claudeleaks.com. It's free, no login, no tracking beyond basic analytics.
If there's an incident I've missed, I want to know. If something is miscategorized or the confidence level on an entry seems wrong, I want to know that too. The whole thing only gets more useful if the underlying data is accurate and complete.
AI security is going to matter more in the next two years than it did in the last two. The tools are getting more powerful, the integrations are getting deeper, and the attack surface is expanding in ways that most developers don't fully track. Having a reliable record of what's already happened seems like the obvious starting point.
So that's what I built.
I'm Akash Muni, the developer behind claudeleaks.com. I build full-stack tools and write about AI, security, and software at the intersection of both.
